Why Retention is King of Growth Strategy
June 15, 2015
Earlier this year at the Weapons of Mass Distribution (WMD) Conference hosted by 500 Startups, HubSpot VP Growth Brian Balfour took the stage to share an incredibly detailed and fascinating break down of how his team uncovers and solves retention optimization challenges.
You don’t see this kind of remarkably practical, transparent, behind-the-scenes tactic sharing often, so the presentation is a must-watch for anyone working to optimize SaaS growth, from the C-suite on down to the front lines.
Note: Brian also writes some of the best tactical essays on growth strategy and customer acquisition/retention around. You can find them at his site: CoElevate.com.
Watch the video or dive right in to the transcript below.
— Brian Balfour, VP Growth, HubSpot |
Transcript
Since I’m one of the closing speakers, I think we should all take a moment to give these guys a round of applause for putting together such an awesome group. I’m very anti-conference, and this is one of the few conferences I recommend for you, so thanks. Real quick, big disclaimer, I’ve got lots of charts, lots of data in this. I love presenting real data. Unfortunately since HubSpot went public, our legal department seriously advised me not to do that this time. So all data in this presentation has been made up, but the learnings are very real. They are 100% real. That’s the most important piece of it. I’m not going to repeat this as well, so just assume every single piece of data you see in this is sort of made up. Basically, I wanted to ask questions like, “What is the most important piece of growth?”
We’ve heard a lot about a lot of things today and we talk about a lot of things about virality, super sexy, talking about the latest viral lab, the latest and greatest sort of acquisition hack, but I think the thing that gets lost in a lot of this conversation is retention. And I think if you walk away from this presentation with one learning, it’s that you don’t have good retention, you don’t understand your retention, literally nothing else matters. Just stop and get a handle on what your retention is and really understanding that.
This is a lot to comprehend here, and I will explain what we have here, but this is what bad retention looks like.
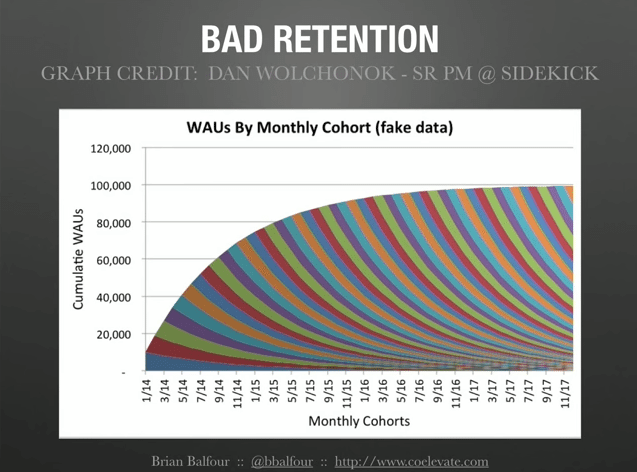
What you see here on all of the different layers are new cohorts of users, new groups of users we acquire, and those groups shrink over time because they aren’t retained.
So what happens is if we were sort of just in the early part of this graph here, we would like we were growing. We would like we were thinking we were doing, but what we don’t realize is under hood there is a really big problem and what we are heading for is basically flat lining, or eventually if we carried this graph out, we’d eventually basically plummet to zero. So no matter what, in this example basically we’re acquiring a similar amount of users, basically week over week or month over month. Eventually we get to a point where it doesn’t matter. We’re basically flat lining growth.
So what does good retention look like? It kind of look like this, where basically every group of users eventually will retain a sustainable amount of them, and these layers start to stack on top of one another. And so that as we acquire a similar amount of users in each group, they kind of stack on each other and actually form sort of an up and right growth curve.
What awesome retention looks like, we can also look at this on a revenue basis and subscription based startups, are cohorts that actually expand in size. This is often referred to as net negative churn. In this case with awesome retention, you really start to get that exponential-looking graph, really sort of up and to the right. But this isn’t it.
Why Optimizing Retention is the Most Important Growth Strategy of All
I’m not going to go through the math, but there is a lot more to retention. So as we increase retention, we actually increase other things. The first thing is virality. As we retain a user for longer and longer periods of time, we get more opportunity to basically get them to invite other users and bring other users into the mix. So the longer that I use Dropbox, probably the more times I’m going to share a folder with somebody who might not be a user. There’s a lot more opportunities to bring users back into Dropbox.
So as I increase retention, I also increase virality. As I increase retention, I also increase LTV. Obviously the longer that I retain a user, the more I’m going to monetize them, no matter what type of startup you are. Even if I’m an ad-supported consumer app like Twitter, the longer I retain the user, the more ads I’m going to serve to that person, therefore the more I’m going to monetize the user.
As I increase my LTV, we have another effect where I can typically afford a higher cost per acquisition at the top of the funnel, and as I can afford higher acquisition cost, a lot of options open up. I might be able to acquire users out of a more expensive audience. I might be able to expand to a channel that was once too expensive for us, but is now actually pretty efficient cost-wise. So as you increase your retention, you increase your LTV and you start to open up things at the top of the funnel.
So there is also another one in sort of premium-based startups. As I increase my retention, I typically increase my upgrade rates as well. We see this in basically one of our products at HubSpot called Sidekick, is that the better our retention is for a cohort, the greater percentage of that cohort we tend to upgrade over time, which basically over time then leads to another effect which is decreasing payback period. I make my money back from my acquisition cost much faster.
There is more to this, but the point is, every improvement that you make to retention also improves all of these other things, virality, LTV, payback period. It is literally the foundation to all of growth, and that’s really why retention is the king of growth.
The 3 Lifecycle Stages of Retention
So what I want to do next is basically talk a little bit deeper about sort of what the anatomy of retention looks like. Retention all starts with cohorts. You all probably are familiar with kind of a cohort graph like this. This is kind of out of mixed panel. The easier way to look at is basically translating these cohort charts into retention curves.
What a standard retention curve looks like is basically taking cohort in over time, looking over time what percentage of that user base is still active. A retention curve basically looks very different depending on what type of company you are, whether you’re an e-commerce startup, a subscription startup, maybe a consumer app or mobile game. But there is one thing that’s kind of consistent between all of them that’s really, really important, and that’s that the retention curve flattens off at some point.
A good retention curve always flattens off at some point. Sometimes that happens really quickly, sometimes that happens sort of longer out, but really bad retention curves are ones that basically eventually end up trending to zero. It might take a while to trend to zero, but if it’s trending to zero, that basically means that at some point in your company’s lifetime, you will end up just starting to churn through all of your users, and your growth curve will look like that very first graph that I showed will eventually flatten off and start to decrease.
Looking at these retention curves is the first step to understanding, but we really need to sort of break it down into pieces because there are different pieces of these curves and we need to treat them all differently. How we optimize them is all very different as well.
Phase 1: Week One Retention (Inspiring the “Ah-ha” Moment)
The first part of retention is basically this first little sliver that you see here. We call it “Week One Retention” for some of the products that we work on, but depending on your product it might be “Day One Retention,” “Month One Retention.” That time frame might be a little different. But this is really kind of your users’ first experience, and the purpose basically in this piece of the curve is all about how you get your users to experience that core value as quickly as possible.
A lot of people refer this to as like the “ah-ha moment.” The common example is “The seven friends in ten days from Facebook,” whatever that metric is. But the real big purpose if you want to improve this piece of your retention curve and understand this retention curve is understanding how quickly you get your users to experience that core value that your product offers.
Phase 2: Mid-term Retention (Encouraging Habit Building)
This differs a little bit from the next section of retention, and we call this “Mid-term Retention.” So after you get them to experience that core value really quickly for that first time, they sort of enter the second part where you need to get user to create habits around that core value. I see a lot of mistakes around this.
A lot of people assume, “Well, if I get my users to understand that core value and experience that core value, it’s so great that they’re just going to continue using my app.” That’s a really big mistake because one of the hardest things to change is obviously user behavior and human behavior. So a big part of this stage is how you get people to kind of rewire their brains, build those habits really build in that repetition so that they continue to experience that core value.
Phase 3: Long-term Retention (Keeping the Spark Alive)
The third part is basically “Long-term Retention.” After they get through this sort of “Mid-term Retention,” it’s about how do you retain them over time? How do you get this curve to flatten? That’s all about how you get your users to experience this core value as often as possible. So even if you get them to experience that core value really quickly and then you build in repetition and get them to rewire their brains and start to build habits around it, you still, over a very long period of time need to figure out how you get that core value in front of them as often as possible.
One of my favorite charts, which I don’t have here is one from Phil Libin, the CEO of Evernote, where he shows a retention curve of Evernote from four years ago, and he shows this flat line for four years straight. That’s because Evernote really worked hard on how they get that core value in front of their users over and over and over again. The job is sort of never done.
Two Fundamental Ways to Optimize Retention
As we start thinking about how to improve and increase retention, because it is the most important element to growth, there are really two fundamental ways we can think about how we influence these retention curves as we approach our optimization efforts.
The first is obviously we can shift this retention curve up. That’s obviously a very drastic improvement in retention, and typically the things that lead to shifting the curve up are two main things. You build new core features into the product. However, this is extremely dangerous because we can trick ourselves into thinking that more product features are just going to help us increase retention when in a lot of cases it’s actually the reverse. It makes your product more complicated, harder to understand and harder to get users to experience and understand that core value really quickly, but it does happen a lot. Sometimes you can build new core features and it helps shift that curve up.
The second way is actually improving Week One Retention. We’re going to talk a little more about this, because even though Week One Retention is that small little sliver, or that Initial Retention, that small little sliver upfront, it actually has one of the biggest impacts on your retention over time, because typically improvements that you make in Week One Retention cascade throughout the entire retention curve. The more people you get to experience that core value really quickly, they tend to retain throughout the whole thing.
The second way that we can improve this retention curve is obviously we can slow the curve down. We can slow the decrease down or we can flatten it off. If it’s kind of trending towards zero, we can look to strategize on how to flatten this off, and this typically happens from one of four main buckets.
- We can refine current features. We can make them easier to understand. We can get them in front of our users more often, and we can build repetition around them.
- We can build in what I call retention hooks. LinkedIn is sort of the master at this. It’s building in features specifically in the product. They give users reasons to basically reach out and send notifications to other users to bring them back into the product. So in LinkedIn’s case it’s all about endorsements and reviews and the skills feature. They’re very good at this.
- The third bucket is improving the overall quality. Obviously, the higher that quality, typically we see this kind of slow and flattening off of this curve.
- The fourth bucket is resurrecting. Out of a cohort of users who might have used the product for a little bit then churned, how do you bring them back to life? This becomes more and more important as your startup grows bigger and bigger in the possibility of the dormant bucket — the bucket of people that you can possibly resurrect — becomes bigger and bigger.
Case Study: Retention Optimization in Action
So then we can talk a little bit about this. I want to kind of walk through some of the work that we’ve been doing at HubSpot and give some examples in the case study. The product I’m going to talk a little bit about is called Sidekick. This is one of our new tools. It’s a freemium tool, kind of like Dropbox and Evernote.
The product is pretty simple. It basically attaches to your email, whether you are using Gmail, Outlook, or Apple Mail, and it basically gives you what we like to call super powers. Special features like pulling in people’s social information from the contacts you are emailing. It lets you see who opens and clicks on your emails, let’s you schedule emails in the future. Very powerful if you’re in like a sales or a BD or kind of like a PR role.
But the product is really simple. Basically I sign up, I install the Chrome Extension or the Outlook Plug-in depending on what client you’re using. And then you basically just start using your email and it kind of sits in the background and provides these features for you.
Sometime last year, we were starting to increase the number of users we were acquiring by quite a bit. We really wanted to be careful and we started to look at our retention curves and we noticed two problems. The first thing was, as newer and newer cohorts came in we saw that over time Week One Retention was decreasing for us and we were pretty nervous about that.
The second thing that we looked at was that it took a really long time, but our curves were actually trending towards zero. Even though it took a really long time, we felt like we needed to basically address that to see if we could sort of fix it. So, we chose to really work on two areas — Week One Retention and basically Long-term Retention, that sort of tail of the curve. I don’t have time to go through both, but the following on what we did is all about some of the strategies we used to improve Week One Retention.
What we did is we followed our growth process. If you’re not familiar with our growth process, this is what I gave a presentation on last year at this exact conference. There is a link in this deck which will be online after this, but it basically looks like this. So the early part of our growth process is all about, how do we basically find levers? How do we identify really high impact areas to work on, set some goals around them, and then start exploring the data.
We’ve already found our high impact areas and we started setting some goals. So this next step was really, how do we explore the data and really start to basically break down this Week One Retention to the point that we can think about it in high actionable pieces? Because we can’t just sit there and basically say, “Okay, let’s come up with a bunch of ideas on how to improve Week One Retention.” We actually have to understand what the inputs are to this output of Week One Retention that we are actually trying to improve. So how do we go about doing that?
Segmenting, Segmenting, Segmenting
The first thing we did is we segmented like hell. We took those retention curves and segmented them by a bunch of different factors, whether it was the acquisition source, the email client they were using, the persona they were, the type of email. We looked at all these different segmentations to see how the retention curves looked differently, how users were behaving based on these different attributes. We found a bunch of different things, but this is one example.
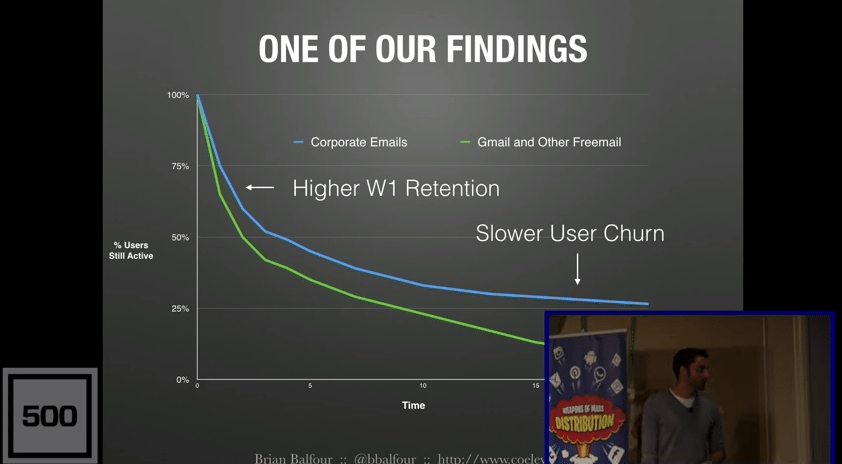
One of our findings was that we looked at the blue one, which is basically people who signed up with corporate emails. The green line is people who signed up with Gmail or other free email. What we found was people who signed up with corporate emails basically not only had higher Week One Retention, but they also had slower users churned over time. So that started to give us hints around what starts to affect Week One Retention. The thing that this told us is that people who entered our product with the work context verses the personal context actually retained a lot better. So we were like, “This is pretty interesting.”
Digging into the Data
We found a few other things in this, but then we also did a second thing. We looked at quantitative indicators. So we looked at basically the quantitative behavior by comparing data between those who churned in week one and those who ended up retaining. You can do all sorts of fancy analysis like regression and stuff, but literally I think it’s very underestimated just getting your hands dirty, getting into the data and just kind of exploring it manually, like looking at these two groups of users, those you retain and those who churn, and starting to basically identify on your own how they look different.
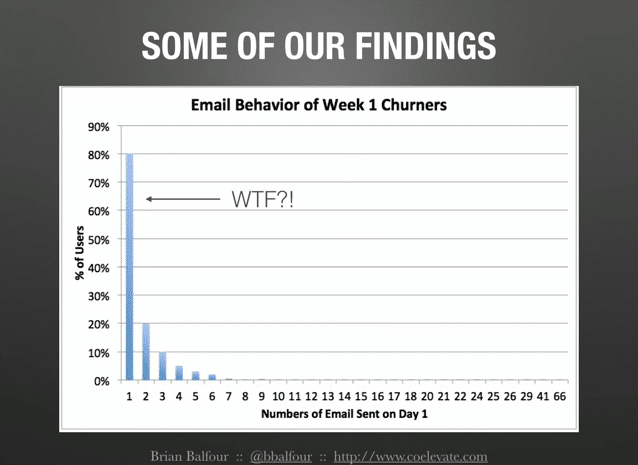
One of the things we found was this, what this chart shows is that out of the users who churned in week one, how many emails did they send on day one? The vast majority ended up only sending one email, and that was really, really confusing to us because basically with our product, once you have it installed in your email, it’s just on. You just have to start emailing and start using it.
So that meant the users were taking a very specific set of actions to either uninstall the product or basically change the settings which was very much hidden within our product to basically turn these features off. This basically started to get us to ask a lot of questions, which led us to the third thing that we did.
Reaching Out for Answers & Feedback
What we do a lot on Sidekick is we collect a lot of one-on-one qualitative data, and the way we do this is not necessarily one-on-one in-person conversations. We send extremely targeted one-on-one emails to users who look like they’re coming from a personal user account asking them very open-ended questions. So in this case what we did is, we started basically pulling a list of users who displayed the previous behavior I showed, sending one email with our product on that first day. We sent them an email and we said, “Hey, so and so, we notice that you installed Sidekick but only sent one email with it. We’re wondering why. We love brutal honesty (smiley face). Please send us some feedback.”
We got tons of responses by doing this, and basically all these responses come in and out of the responses what we do is we keep asking the question “why?” Out of the people who talk, we just get them to keep talking. We just say, “Oh, that’s really interesting, please tell me more — and more and more.” And as we do this, we collect all of these responses and we start categorizing them, and we end up with a bunch of different categories and trends for this reason that these users are displaying this specific quantitative behavior.
So we look for a lot of things in this, but one of the main things we look at is not only the category of reason that they’re describing, but the language that they are using to describe the problem. We had this big segment that basically didn’t understand the product, but the language that kept coming up was they didn’t have time to figure it out. Once again we found that really confusing because there was nothing to figure out after you installed the product. You installed the product and you just started to send emails and the product started to work.
It started to track emails for you, it started to pull in the data, all that stuff. Anyways, we collected all of this data and by the end of these three things, we started to get a lot of big hypotheses around what was causing this week one churn. So we went into the next step of our process.
Testing Solutions
We started brainstorming ideas against all of this qualitative and quantitative data. We started prioritizing these ideas. We started designing what we call “minimum viable tests.” The first test that we ran was, we looked at the first landing experience of our product.
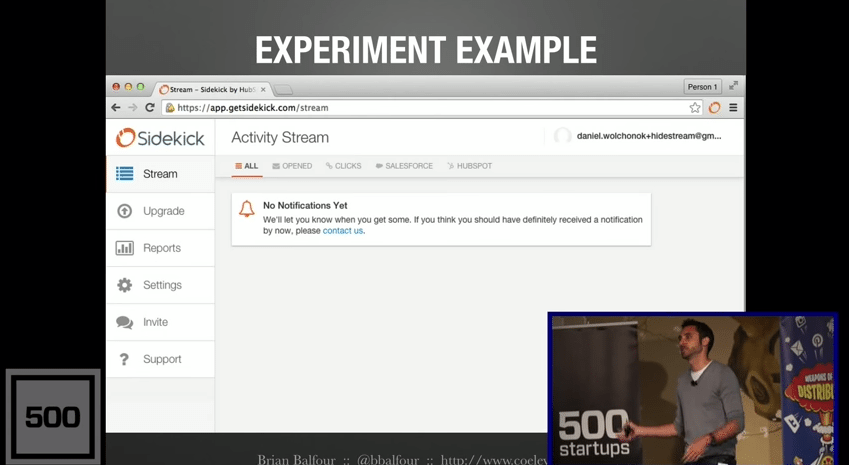
This is what it looks like after, but before this we had 19 different call to actions on this page. It was crazy. It was like a Frankenstein page that had been put together over time.
So we were like, “You know what, people are saying they don’t have time to figure it out because this page is just way too confusing.” So we were like, “As a start, let’s just clean it up. Let’s just basically take away all of the CTAs. That’s definitely going to work.” That failed by a lot, and so we were like, “Okay, you know what it is? It’s because we need to basically explain what this is going to look like after they start using the product a little bit more.” So what we did is we added a bunch of different example notifications in there of what would appear there along with tool tips explaining the different use cases behind each one,” and we were like, “Oh man, this is definitely going to work.” That one failed. It did not improve retention.
So we were like, “Okay, maybe they just need deeper or more education.” So we threw a video explaining the product. That failed. Anyways, 11 experiments later, all failed along this major hypothesis, we basically took a step back, and we were like, “All right, it sounds like we’re going down the wrong hypothesis here.”
So we revisited two steps in our process, basically all of the learnings that we had gathered from all of our experience as well as all of the data that we had collected in the exploration data, and we were looking at all the learnings describing how people responded to all of these experiments and the language that they were using. Basically, what we did is, we came up with this hypothesis that it wasn’t about improving the learning experience, it was the entire experience, itself. Meaning we were advertising a product about your email in your landing page, we had you install the product within your email and then your first experience was basically to this web page within a web application. We were like, “In hindsight, that’s really obvious.”
To test this hypothesis, we didn’t redesign the whole experience. We didn’t do anything. Literally after they installed the product, we showed them this. We said, “You’ve successfully set up Sidekick. Head over here to your inbox to start sending emails.” We didn’t let them into the web application. We actually discouraged them from going to the web application. It sounds crazy, right? We were like, “No way this is going to work.” That won. That actually improved our retention.
Now we have really quickly validated this new hypothesis around Week One Retention — it’s not about explaining the thing within the web application, it’s about not even sending them to the web application as a whole. So we started rethinking the entire experience based on this major hypothesis. We ran about 68 more experiments and the end result was this, basically two really positive things:
- As we started making improvements, our more recent cohorts shifted up. We saw the Week One improvement. Week One improvements were cascading throughout our retention.
- Then some of the Long-term Retention stuff which I haven’t talked about also flattened these cohorts off. So a lot of big wins.
5 Strategies HubSpot Used to Improve Retention
What were the strategies that we did to basically attack this?
1) Focus on the New User’s First Experience
We started thinking about the new user experience almost as its own separate application. This is really common now, sort of in hindsight.
When you sign up for something like Twitter or Facebook, the experience looks totally different than the main application. It almost looks and feels like a completely separate application because that experience is very specifically designed to basically get users towards a very specific set of actions. So we started thinking about Week One Retention, that segment of our retention curve, almost as its own separate application.
2) Segment Based on Persona
You can segment in a bunch of different ways. In Pinterest for example, you actually receive a very different experience if you sign up and you are a male verses a female, which very much makes sense. They used to have this problem where a bunch of males would sign up and since it was such a female-heavy audience, they saw all these female-oriented content and of course they churned right away.
For us it wasn’t about male verses female. That wasn’t the segmentation that worked for us. It was more based on persona, whether you were a sales person or a marketer or in a different functional role, because no matter what, they all use the same feature set, but they use it in very different ways. We needed to use very different language to explain how this all worked to them.
3) Provide Users with Context
The third thing we did was that first thing that I hinted at, is that we played around with how we switched the user context from personal to work. We tested everything from basically just simple language changes to if they signed up for a Gmail account, we forced them to enter their work account to basically sort of softer cells and everything on that spectrum. But what we did a lot about is we found the context that users entered with that helped them retain and understand the product easier and tried to switch them within that context right away.
4) Test Different Formats for Support/Onboarding Materials
The fourth thing we did is that we really tested the medium of education. We tried a bunch of different things, whether it was tool tips or videos or static images and I think that a lot of people kind of assume, was this video better for my audience or so and so. We actually found that there were very drastic differences between the mediums of education that we used for different audiences.
5) Experiment with Providing Content on a Consistent Basis
Last but not least, we kind of found this on accident with content. We were auto subscribing some of our users to the content that we are producing on our blog. And one day, I don’t know how we stumbled on this data, but we looked at this and we kind of broke this down and we realized that users who were receiving our blog content — it wasn’t even about the product, it was about a bunch of other things — actually retained significantly higher for us.
3 Retention Challenges to Overcome
So we’re continuing to validate this and optimize this, but these five strategies led to very significant results on retention without even introducing a new feature into our product. Along the way, we learned a lot of challenges about how you go about and optimize and think about retention. Here are a few.
1) Churn Can Be Sneaky
One is that it’s really sneaky. Retention problems can really sneak up on you, so it looks like a lot of times your top line growth can be growing, but under the hood, there are a lot of problems that are going to sneak up on you a little bit later.
2) Experiments Take Time
The second thing is what we call “soak time”. Different experiments need a different amount of time to get to valid results. And retention experiments by nature need a longer time to soak because you have to see how cohorts of users behave differently over time. There are ways to combat this by using different leading indicators. But to get true and fully valid results, you really need to let these things soak over time, and what this does is it reduces your throughput of experiments and kind of slows down progress. That was one of the big challenges we ran into.
3) Building a Large Enough Sample Size Can Be Tough
The third is just getting the cohort sizes that we needed was a little bit tougher than doing kind of top or final experiments with our ads and our content. But we eventually battled through these three things.
That’s it. A special thank you to our Senior PM and our team that did a lot of the hard work behind this. He is here in the audience and both of us will be happy to answer questions afterwards if you’d like about this or anything else we do on sort of the HubSpot. And if you are interested in diving more into retention stuff, my website is at the top. Jamie Quint who spoke today has a couple of really good resources and models on retention, and David Skok from Matrix Partners also has a bunch of good stuff on his blog as well.
Photo by Ryan McGuire